はじめに
LLMの日本語に関する評価にはJGLUEデータセットを使用するlm-evaluation-harness というプログラムがあります。(提供してくださった方々、ありがとうございます)
弊社でもこのlm-evaluation-harnessを使用してファインチューニング用のLLMの評価や事後の劣化具合評価に使用しているのですが、lm-evaluation-harnessにはプロンプトのバージョンが0.2から0.6までの種類があります。プロンプトバージョンはtasksの「(タスク名)-(タスクバージョン)-(プロンプトバージョン)」(例: jsquad-1.1-0.2)で指定します。
LLMの評価にあたって、このプロンプトバージョンをその時の最新である0.5に固定して使用していたのですが、どうもLLMによっては著しく低い値が出るものもありました。
ひょっとしたら、LLMによってプロンプトによる得意不得意があるのではないかと思い、総当たりで調べることにしました。
評価対象
評価は以下のhuggingfaceで公開されている(OSSである)代表的な日本語LLMを対象としました。いずれも最近公開されたものです。
- cyberagent/calm2-7b
- cyberagent/calm2-7b-chat
- elyza/ELYZA-japanese-Llama-2-7b
- elyza/ELYZA-japanese-Llama-2-7b-instruct
- rinna/japanese-gpt-neox-3.6b
- rinna/japanese-gpt-neox-3.6b-instruction-ppo
- stabilityai/japanese-stablelm-base-gamma-7b
- stabilityai/japanese-stablelm-instruct-gamma-7b
- meta-llama/Llama-2-13b-chat-hf
- meta-llama/Llama-2-13b-hf
- llm-jp/llm-jp-13b-instruct-full-jaster-v1.0
- llm-jp/llm-jp-13b-instruct-lora-jaster-v1.0
- llm-jp/llm-jp-13b-v1.0
- pfnet/plamo-13b
- pfnet/plamo-13b-instruct
- stockmark/stockmark-13b
- stockmark/stockmark-13b-instruct
評価方法
W&BのLaunchに連続投入するために改造した以外はほとんどの素のlm-evaluation-harnessを用いて以下の4つの日本語タスクを評価し、それらの平均を取りました。
- jsquad-1.1
- jcommonsenseqa-1.1
- jnli-1.1
- marc_ja-1.1
プロンプトの中身
各プロンプトは以下のように定義されています。サンプルは選択肢あり問題のJCommonsenseQAの場合の例で、質問文は{質問}、選択肢は{選択肢0〜4}、正解は選択肢0とします。
0.2: FintanPrompt
prompt template is taken from ChatGPT vs BERT: どちらが日本語をより理解できるのか?
質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。なお、回答は選択肢の番号(例:0)でするものとします。
質問:{質問}
選択肢:0.{選択肢0},1.{選択肢1}, ...,4.{選択肢4}
回答:0
0.3: AlpacaPrompt
This prompt format was inspired by the below data in fujiki/japanese_alpaca_data.
以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。
### 指示:
与えられた選択肢の中から、最適な答えを選んでください。出力は以下から選択してください:
- {選択肢0}
- {選択肢1}
:
- {選択肢4}
### 入力:
{質問}
### 応答:
{選択肢0}
0.4: RinnaInstructionSFT
Reference: - HF Hub: https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-sft
見やすくするために<NL>の後に改行を入れていますが、正式には改行なしの1行です。
ユーザー: 与えられた選択肢の中から、最適な答えを選んでください。<NL>
システム: 分かりました。<NL>
ユーザー: 質問:{質問}<NL>
選択肢:<NL>
- {選択肢0}<NL>
- {選択肢1}<NL>
:
- {選択肢4}<NL>
システム: {選択肢0}
0.5: RinnaBilingualInstructionSFT
Reference: - HF Hub: https://huggingface.co/rinna/bilingual-gpt-neox-4b-instruction-sft
ユーザー: 与えられた選択肢の中から、最適な答えを選んでください。
システム: 分かりました。
ユーザー: 質問:{質問}
選択肢:
- {選択肢0}
- {選択肢1}
:
- {選択肢4}
システム: {選択肢0}
0.6: Llama2
This prompt version follows the Llama2-chat's prompt format:
<s>[INST] <<SYS>>
あなたは役立つアシスタントです。
<</SYS>>
与えられた選択肢の中から、最適な答えを選んでください。出力は以下から選択してください:
- {選択肢0}
- {選択肢1}
:
- {選択肢4}
質問:{質問} [/INST] {選択肢0}
評価結果
結果は以下のようになりました。絶対値ですと各LLMの性能がモロに出てしまいますので、各LLM内での相対比率を出すようにしました。
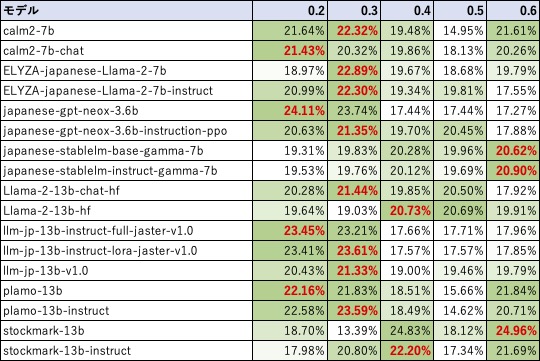
- 結果を見ると、プロンプトバージョン0.3が一番人気であることが分かりました。
- 逆に私が評価していたプロンプトバージョン0.5は最も不人気であるため、値が著しく悪いのも納得がいきます。
- LLMによってはプロンプトバージョンで極端に差がついたりするものがあったり(濃淡がくっきりしている)、あまり差がつかなかったりするものがあったりして興味深かったです。
- プロンプトバージョンの0.4〜0.6はRinnaやLlama2向けと書かれているが、対象が全くヒットしていなかったのが面白かったです。
おわりに
総当たりで調査すると、各LLMの特徴が浮かび上がってきて面白かったです。 そして、LLMを調査する時のプロンプトは無難にFintanPrompt(0.2)かAlpacaPrompt(0.3)を使った方が良さそうです。
また、今回は絶対値を出しませんでしたが、llm-jp-13bが良い性能を示していましたので、しばらくのベースモデルはllm-jp-13bにしようかと考えています。